
I was on a coding knowledge evaluation site today and one of the Python questions asked about which comparison expression would be faster. The choices were:
1. if L < x ** y <= R:
2. if x ** y > L and x ** y <= R:
3. if x ** y in range (L + 1, R + 1):My thinking was that with modern compiler (or the Python interpreter) optimizations, both 1 and 2 would be exactly the same. In fact, the Python documentation says just that.

However, the coding site said the correct response was 1. So I decided to put it to an empirical test.
I wrote a couple of scripts that call a function that performs the comparison each way.

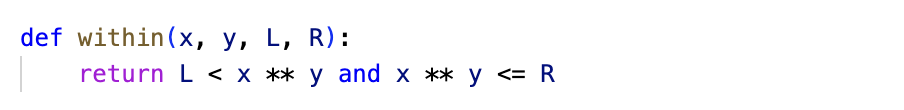
The scripts call their respective functions ten million times, with random values for x, y, L and R so that the results are not influenced by the values or some other caching optimization.
To my surprise, the chained comparison L < x ** y <= R was slightly faster, a difference that becomes significant at scale.

Get the bytecode!
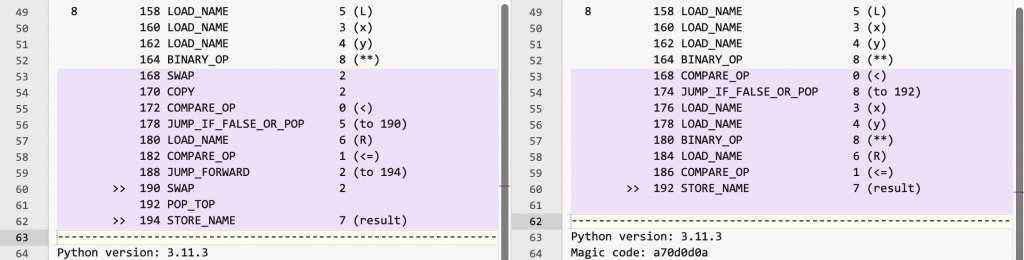
Delving into this deeper, I compiled the Python language files to their bytecode representations, and then compared the bytecode instructions. The text on the left represents the chained-comparison expression, the text on the right represents the two comparisons joined by the and operator.
I’m by no means a Python bytecode expert, but it’s clear that the code on the left duplicates the result of the power operation x ** y and saves it for later (lines 43-44 in the margin, instruction lines 72 and 74). Whereas the and-joined comparison code on the right recalculates the power operation (line 47 in the margin, instruction line 80).

I then wondered whether these differences were limited to whatever Python version I was using. That turns out to be:
Python 3.10.7 (v3.10.7:6cc6b13308, Sep 5 2022, 14:02:52) [Clang 13.0.0 (clang-1300.0.29.30)] on darwinCode language: plaintext (plaintext)I then retraced my steps using the homebrew-installed Python, which is a different version:
Python 3.11.3 (main, Apr 7 2023, 20:13:31) [Clang 14.0.0 (clang-1400.0.29.202)] on darwinCode language: plaintext (plaintext)The bytecode is still different, but also different from Python 3.10, at least in the instruction names.
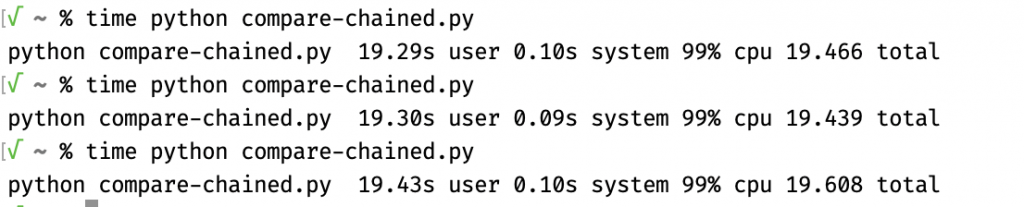
I timed the execution of two comparison scripts and the difference was so small that it would take a statistical test to determine whether it is valid. However, the difference in runtimes between Python 3.10 and Python 3.11 was much bigger, bigger than the difference between the two comparison methods using Python 3.10.

I already went farther down the rabbit hole than I’d intended to, so I figured I’d stop here. The tl;dr is that there is a difference in the resulting bytecode and performance between L < x ** y <= R and x ** y > L and x ** y <= R when using Python 3.10, but while the bytecode is different in Python 3.11, the performance difference disappears and the overall performance also improves. While the coding site was correct in the context of Python 3.10, I was (unwittingly) correct in the context of Python 3.11.
So switch to Python 3.11!