
In a previous article, I showed how to set up a web application to use microservices with just the bare minimum of effort. However, that can result in some limitations, such as the presentation layer (or API Gateway) that aggregates the results of the microservices using hard-coded endpoint addresses (e.g. http://localhost:8888/api/v1/fromurl).
In actual practice, this should be avoided, because the host is unlikely to be local, but rather an IP address or a symbolic name, which could change, if not from day to day, then sometime. The port number could change too. To solve this, a microservices architecture would need a registry of some sort that could keep track of services. There are a few readily available, but I decided that in this case, I would try to write my own, just to get a flavor of what’s involved. I also was curious to see how one might go about solving one of the security issues that I see with microservices: how can rogue services be prevented from registering and getting used.
How would one go about setting up a registry? Let’s start with what it needs to do. In many situations, the registry can play either a passive role, waiting for services to act, or an active role, or it could do both. Let’s see:
- It lets services enroll themselves/It goes out and discovers services
- It lets service clients look up services/It sends out notifications of what services are available
- It listens for periodic “heartbeat” signals from services/It sends are-you-there messages to services
Enrollment vs. Discovery
If services have the responsibility of enrolling themselves with a registry, then the registry address is probably going to need to be fixed and partially hard-coded in the services, otherwise they’ll need a registry where they can look up the registry, recursing infinitely. The registry location could be made available as an environment setting, but if the registry address changes, the microservice will at least have to be restarted. Nevertheless, self-enrollment seems like a fairly simple design to implement.
On the other hand, if the registry needs to go out and discover the services, the situation gets more complicated. The registry needs an address and/or port range to search over, it needs to know how to identify a microservice from some other kind of web service or API server, and it needs a defined frequency with which to scan to learn about new services. This approach could create unwanted network spam traffic and security issues (it could conflate legitimate registry scans from malignant scans). However, discovery scans could also serve as presence tests to see which services are still available.
Service Lookup vs. Broadcast
A registry could wait for clients to look up the services they need. That way clients may get an almost real-time status of service availability (almost because any service status that the registry has may already be outdated by the time it receives it). Depending upon the number of clients and the number of services they use, this could make the registry very busy. To relieve the registry load, it’s possible that clients could cache the lookup results for some period of time.
Conversely, the registry could periodically broadcast which services are available. Then it wouldn’t be so busy. However, this could lead to the possibility that clients are operating with outdated information.
Which approach is best depends on how often services become unavailable or new services come online, and how critical it is for clients to have the latest status.
Collecting Heartbeats vs. Pinging
Similar to enrollment and service lookup, the registry could listen for service heartbeats. Whenever it receives a heartbeat from a service, the registry could set the last-contact time for that service. When clients look up a service, the registry would check the time elapsed since last contact, and if it is within some threshold, provide the address. It could also provide an indicator of quality. Clients could then use that to adjust their timeout periods, for example.
(As an aside, providing stale information rather than no information seems like a bad idea. Recently my phone didn’t have a signal inside the hotel I was staying at, so it showed me the last weather forecast it had. When I went outside, the weather had changed dramatically.)
The registry could also periodically ping every service that it knows about to see whether it is still there. This approach could go wrong if the service was too busy or some other network issue caused the server to not get a response and consequently mark the service as erroneously unavailable.
Time to Choose a Strategy
Picking a strategy for one aspect of the registry impacts the choices for the other aspects as well. It seems like service initiated enrollments and heartbeats go hand-in-hand, while discover and ping are more compatible together.
Client lookup vs registry broadcast of available services has no clear winner, though with broadcast the system would also need a messaging queue, so that’s just shifting the load elsewhere. Client-side caching might have the same net results as broadcast, as opposed to 100% on-demand lookups.
With that discussion out of the way, it’s time to pick some options. I chose service registration/heartbeat, and client-initiated lookup. This may not be my choice in a live system, but it’s what I chose to build for this exercise.
My registry is implemented using almost the same pattern as the other micro-services. It is a Tornado web app that listens for POST messages from services wanting to enroll themselves, and GET requests from clients looking up services. It has two API endpoint handlers, RegistryHandler and HeartbeatHandler. Let’s take the RegistryHandler first.
Microservices use the POST method to register themselves. In the sequence diagram below, this is step 1. A microservice sends its name, server (either hostname or IP) and the port where it listens. In order to mutually authenticate the registry and the service, the registry initiates a separate request (step 2) to a Verify endpoint of the microservice, using the connection information that the service provided. This is the http_client.fetch line in the post method of the code above. The server sends a known challenge query, and the service must send back a pre-agreed response. The response from the service is processed in a handler method that is in the same file as the RegistryHandler class above:
In addition to the challenge/response authenticaton, the registry also sends a session secret that is unique to this microservice, so that in the future the registry recognizes this service as one that it has already authenticated. In practice, all these authentications could be done using PKI, but to demonstrate the concepts, for now, they are done using plain text strings.
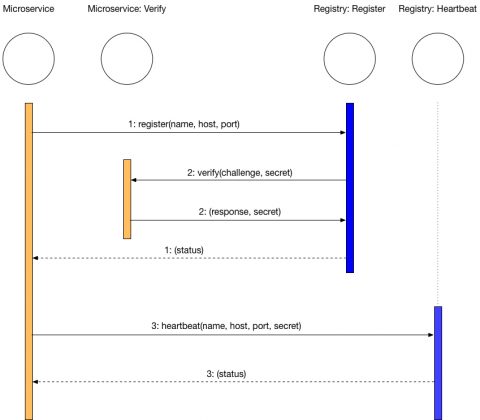
On the microservice side, the registration process is the same across all services, so this creates a good opportunity for doing some refactoring and creating an abstract base class that encapsulates the registration and heartbeat methods.
The Microservice class defines a start method, which must be called by whatever process or command runs the microservice. This start method creates the Tornado app (make_app), sets up the port, calls a method to register the microservice with the registry ( register_service ), and sets up a “pinger” that runs in a timer loop and performs the heartbeat function.
Subclasses of Microservice must implement a nested Meta class and a handlers method. These are discussed further below. The Microservice class also sets up a handler called VerificationHandler, which responds to the verify request from the registry during the initial registration step. VerificationHandler just checks that the registry provided the correct challenge, then sends back the same connection information as before, taking it from the Meta nested class that is passed in, and the secret that the registry sent.
Hard-coding the microservice address information in a nested Meta class makes it less dynamic, of course, but it does the trick for this example. However, this lets the Microservice parent class read the properties whenever it is instantiating a new VerificationHandler class (which is only done once, in this example). The other requirement imposed by Microservice is a handlers method, which supplies the handlers that will provide the desired functionality of this microservice. This is how a concrete child class looks:
With the registry in place, a client that needs to use a microservice can look up the service by name in order to get its address.
The line marked (1) shows the client looking up a service in the registry. The response comes back as JSON so in (2) the client code extracts the HTTP response content as a JSON object and gets the data field. In (3) the client uses this information to prepare the call to the microservice API. Just for comparison, line (4) shows how to make an API call when everything is hard-coded.
For developers, writing a microservice is not difficult. However, the architecture and design need to be well thought through, or else managing microservices can become very complex. Just as one example of that, note that the service that extracts the job-description text is customized to work on a Dice.com page. For this entire application to be more useful, it should also be able to handle other job sites. As microservices for new sites are written and deployed, they too will register themselves, so that part is dynamic. However, for the client to also dynamically take advantage of new services, it has to know how to look up new services and what they do. That requires a lot more consideration than one would see in a high-level architecture diagram.
Finally, there has to be an organizational aesthetic to how services are deployed. For example, suppose that microservices for another five or nine job sites are deployed. Now there are ten microservices that all pretty much do the same thing, but in a specialized way, along with two microservices that do something completely different, all on the same registry. That may be fine, but if this proliferates to hundreds of services, it may be better to organize them differently, or use different registries, and so on.
So there you have it, a microservices based app with an API gateway and some basic dynamic registration of services. The full code is available on GitHub, and you can try the full app here.