

When people think of DevOps, they likely think of delivery of code into production. Microsoft, Amazon and DevOps.com all mention delivery in the first paragraph of their definitions of DevOps. However, code has to be developed and tested before it can be shipped. That requires an environment where developers can integrate their code, an environment where QA teams can perform functional and regression tests and one where end-user representatives can perform acceptance testing (UAT). If there are multiple concurrent projects, then multiple such lower environments will be required.
At any organization, as the number of projects that software developers undertake increases, it will face a constraint when it comes to development environments. The choice becomes one of sharing environments among projects, manually creating new environments, or automating the creation of new environments.
Sharing environments can work at a small scale, but with growth it will likely become unwieldy, since it would create coordination overhead and possibly delay shipping code. The second option, of hand-creating new environments, is not viable. In a realistic scenario, some of the tasks involved in creating a new environment include initializing and deploying dozens of microservices and apps, creating and populating multiple databases, mounting shared network drives, and creating load balancer and DNS entries. Once an environment is set up, there are additional, ongoing tasks, such as deploying new versions of services as they go into production or making database changes. It would take a large team just to tend to environments if a company takes the manual route.
Automating the creation of new environments opens up exciting possibilities of creating practically limitless new environments. These environments could self-update when new service versions go into production, and they could have built-in monitoring and alerting. The technical challenges involved in creating the automation are intriguing. It is an opportunity to grow and substantiate the DevOps team’s knowledge and understanding of the various systems involved, including Kubernetes, cloud services, database and data handling, APIs and git.
Ideally, we would want a tool that could be used by the project management team, rather than only by DevOps. That way, the project managers can create new environments as the need arises, removing the dependency on DevOps and freeing up time for the DevOps team to pursue other tasks.
The following sections suggest a way to meet this challenge. While many of the solutions described below are AWS-centric, they could also be applied to other cloud providers.
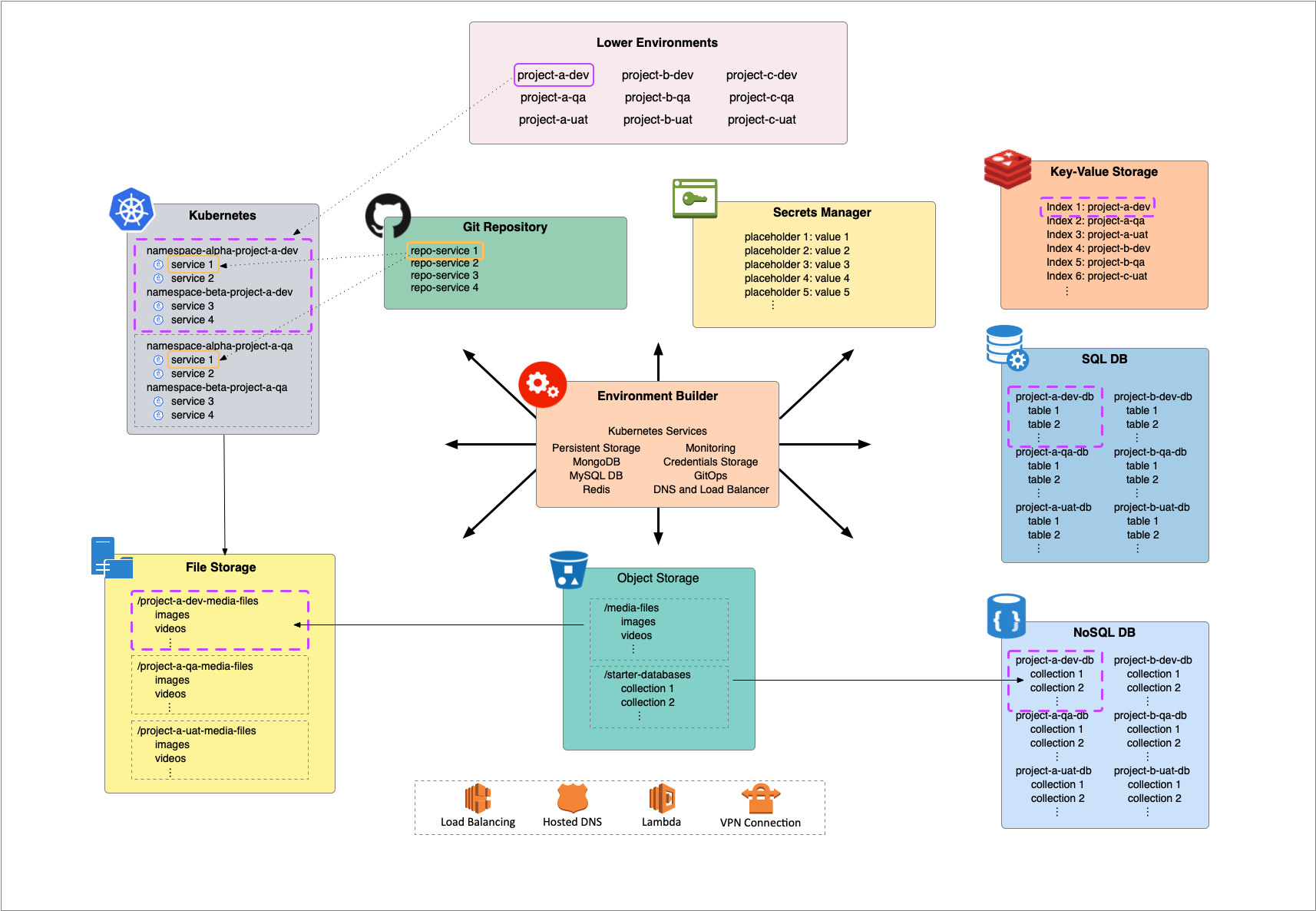
Imagine a small enterprise with a handful of web properties. A fully configured test environment may include at least some of the following components, as well as others not mentioned here:
- Kubernetes Services
- Persistent Storage
- NoSQL DB
- Relational DB
- In-Memory DB
- DNS and Load Balancer Entries
- VPN
- Credentials Storage
- GitOps
- Monitoring
Let us say the company has three current software projects. The goal is to create development, QA and UAT lower environments for each project. We would end up with environments as follows:
| Development | QA | UAT | |
| Project A | proja-dev | proja-qa | proja-uat |
| Project B | projb-dev | projb-qa | projb-uat |
| Project C | projc-dev | projc-qa | projc-uat |
In this scenario, the environments are labeled proja-dev, projb-dev, projc-uat, etc. The base domain name for each project follows the pattern proja-dev.example.com, projb-dev.example.com, projc-uat.example.com, etc. Then, in each environment, the services can be addressed as service1.proja-dev.example.com, service2.proja-dev.example.com, service1.projb-dev.example.com, and so on, or, if so desired, as services.proja-dev.example.com/service1, services.proja-dev.example.com/service2, services.projb-dev.example.com/service1 and so on.
Kubernetes Services
Since services are deployed to Kubernetes, it is imperative to automate the creation and deployment of new namespaces and services. This is where a tool like Helm could be useful, or you could also write your own code. The key here is to templatize the service configuration YAML files. Values that need to change between environments are parametrized. The Helm way, for example, is to use {{PARAMETER-NAME}}.
Most of the file contents would stay the same from environment to environment, but some sections, such as namespaces, volume mounts, would need to be customized. Thus, a shared disk volume named images would be specified as vol-media-{{ENV_NAME}} in the YAML file, where {{ENV_NAME}} is the placeholder. At the time of deployment, {{ENV_NAME}} is replaced by the specific environment name, such as projc-dev, so that the resulting volume name is vol-media-projc-dev.
Persistent Storage
Sometimes an app may require disk storage with pre-populated content, such as images, video files or other content. It is possible to create environment-specific subdirectories in a network drive such as EFS, and then map the subdirectory to Kubernetes persistent storage. The source content would be stored in an easily accessible object store like S3. The tool would need to have access to the EFS volume in order to create the subdirectories. Another option is to use a lambda function to create the EFS subdirectory. Since the data copy into the subdirectory from S3 could take a long time, one option is to make it asynchronous using a service such as AWS DataSync .
DataSync requires a running EC2 instance (called an agent) to perform the file transfer. Each source and destination for the file copy are called locations. After creating locations, the next step is to create a task that connects a source and destination location. Finally, the task must be run in order to copy the files.
By setting up event notifications when S3 contents change, the tool could be configured to rerun the DataSync tasks for all environments.
As a last step, the build tool can use Kubernetes APIs to set up persistent storage volumes mapped to the EFS subdirectories for the specific environment. Using cloud storage such as EFS removes any limits on the number of environments that can be create or amount of content that is loaded in.
NoSQL DB
Most apps and services need some type of a database and no-SQL DBs such as MongoDB are increasingly the choice. We may also want the database to be pre-populated with some starter data, so that apps are ready to use with users and content.
One way to clone multiple databases within a server is to add the environment name to each DB name. In order to maintain security best practices and prevent mixing up of databases, each environment should have its own DB user with a unique password.
In addition to creating the database, the build tool needs to create collections and populate them with documents. The starter data can be stored as JSON files in an object store such as S3. Each S3 folder would represent a database and each file would be a collection. The tool would insert the records in the files into collections in a new database when an environment is created. Database indexes can also be stored as JSON and created during the process. The same is true for data manipulation JSON scripts that customize data to the environment, such as updating URLs with the environment-specific hostnames or random values.
Relational DB
Of course, relational databases continue to play a vital role in many organizations and may be required in test environments. The basic approach to initializing and populating the database would be the same as for a NoSQL database. The data definition statements and data manipulation statements can be stored in files in S3. In this case, since the statements define database and table names, the statements would need to be separated so that the creation can come first, then the insertion, and finally any constraints and indexes that need to be applied could come last.
If the starter data contains a large volume of data (for a data analytics application, for example) and the insertion takes too long, it may be possible to use other approaches, such as the LOAD command in MySQL. The LOAD call is blocking, so for larger tables this can take a few minutes.
In order to customize the data for an environment, it is possible to either perform a string replacement in the INSERT statement or in scripts that alter data after insertion. The second approach may be more time efficient. Constraints (indexes and foreign keys) can also be stored as SQL statements executed after all data manipulation is complete.
In-Memory DB
Modern services architecture involves some form of in-memory data storage, such as Redis, for keeping ephemeral or quick-access data. It would be wasteful to create a new server instance for each environment, nor would it be efficient to launch a new process on a different port. Depending on the particular tool, it may be possible to partition the database so that each environment has its own namespace. For example, Redis database index numbers allow a single instance or sentinel group to be shared among multiple environments.
The environment builder tool can keep track of which indexes have already been assigned and assign an unused index to the new environment. Redis comes with a default limit of 16 indexes, so it may need to be extended to accommodate more environments.
The builder can then restore starter data that was serialized and stored in S3.
DNS and load balancer entries
Many organizations’ production ecosystems contain anywhere from a handful to dozens of websites. As each environment is created, the environment-specific domain names of these sites must be added to a DNS registry. Not all of them may need to be in development environments, but even if only a handful are needed, as the number of projects grows, there will be a vast proliferation of hostnames. If the names are added to the public DNS, that creates a vast attack surface for threat actors to try to gain entry into the system.
The solution is to use a cloud hosted DNS registry, such as AWS Route53. By using internal-facing zone, no matter how many environments are created, the external domain-name footprint does not grow.
Since the DNS is closed to the public Internet, the traffic to the load balancer will not be coming from the public Internet. Therefore, along with an internal zone, it is possible to use an internal-facing load balancer. Cloud service API calls may be used to set up specific load balancer rules and target groups for each environment.
VPN
The section on DNS and load balancers suggested using internal-facing configurations for both. Therefore, in order to connect to the lower environment websites and APIs, users will need to connect to the cloud network they are only visible therein.
One option is to create a VPN link between the corporate network and the cloud. Then users can connect to their company network either on premises or through VPN. Thereafter, the traffic destined for the cloud network would pass through the VPN link. This approach requires work on the part of the company infrastructure group to set up routes and DNS lookups.
Another approach is to use a cloud client VPN to connect directly to the cloud network. In the case of AWS, this would be the AWS Client VPN. Once someone connects to the VPN, their device is internal to the AWS network can resolve internal DNS names and connect to internal IP addresses. For developers, this means that log and database servers also become accessible through DNS names that map to internal AWS IP addresses. None of this is exposed to the public Internet.
Credentials Store
Referring back to the Kubernetes Services section, recall that the service configuration files use placeholders for environment-specific values. It may make sense for the tool to store these values that are specific to an environment, such as API access tokens, in its own data store. They should be available to developers so that they can look up a database password if necessary.
In addition to environment-specific secrets, services may need other secrets and credentials as well, such as API secrets to Twitter or some other SaaS platforms. These credentials may need a higher level of access privilege. These secrets may be stored in the cloud provider’s secrets manager or a third-party tool such as Vault. In AWS, the secrets manager is called Secrets Manager.
The build tool can collect all the secrets, whether from its own store or from Secrets Manager, perhaps from a database, and replace any placeholders it encounters in config files or database scripts. Removing all secrets from the YAML files makes it possible to store the Kubernetes service configurations in a git repository. That then paves the way for the final piece in the solution, which is to trigger deployments and patches via git commits.
Git Ops
As systems grow in size and the number of services increase, it becomes exceedingly difficult for DevOps engineers to maintain the systems manually and individually. The future is in template-based operations, wherein a change in a file triggers a change in deployed systems. One implementation of this model is git-driven operations, or GitOps as it has come to be known.
In the GitOps paradigm, changes to service configuration files in a git repository drive deployments or updates to live systems. The environment builder tool may set up its own repository, or it may be possible to configure it to use existing repositories on a per service basis. Like most CICD tools, it would then register itself as a webhook with the git repository so that it can receive change notifications.
At first, all services start out configured to be in sync with the master branch, but developers could change that on a per-environment basis when they are working on a service. When the service goes to production, the dev team would need to merge the configuration changes into the master branch. The tool could then look in prod to get the Docker image tag and deploy that image in all lower environments where it is newer than the currently deployed image. It is also possible to store all starter database files in a version control repository instead of an object store. It may be helpful for developers to experiment with data structure changes this way.
Monitoring
As the service mesh increases in size and dependencies, monitoring for anomalies becomes more critical, even in lower environments. Whether the approach to monitoring uses API calls or a tool such as Prometheus, the build tool can again set up the collectors and dashboards for each environment. To the tool, the dashboard would be similar to any other service, but it would need to customize the URLs for the environment.
Conclusion
A tool to build lower environments as described above could cut the DevOps lead time to build one environment from days to minutes. If an organization launches 1-2 new projects a quarter, this could cut several weeks of work down to minutes.
Web applications rely on a number of components, such as databases and messaging services. Developers can set up sandboxes on their own machines using virtualization, but there is also a need for environments where others, such as product owners, can view the work. CICD tools automate the deployment of code but there is a lack of tooling to easily set up new environments. The ideas mentioned above are easy to implement and can boost developer productivity. Additional features, such as database refresh/reset on demand, and the ability to add custom data manipulation scripts for specific environments, can put substantially support development teams.